
Encoder is the next generation of Text Refiner is fully integrated into the Meta-Editor, features an updated, user-friendly interface, and supports dictionaries and rule-based coding.
Text Refiner is an add-on module that must be enabled separately on the server.
The system role Coder is required to work with the Text Refiner.
Text Refiner is designed to efficiently transform open-ended responses into categorized clusters using dictionaries, rules, and string similarity algorithms. This ensures users have a streamlined, accessible tool that simplifies data analysis and converts free-form answers into neatly categorized variables.
This article serves as a comprehensive guide to using the new Text Refiner interface.
Dataset preparation
When uploading a dataset, ensure that the variables to be coded are recognized as text variables. To do this, specify the TXT variable type in the codebook and upload the dataset and the codebook together in a single archive.
Access to the Text Refiner is available only for databases uploaded after September 2025. If you don’t see this option for your dataset, you’ll need to re-upload the database.
After the database uploading, go to Meta-Editor → ‘Snowman’ icon to open the menu → Refiner → Create new refiner.
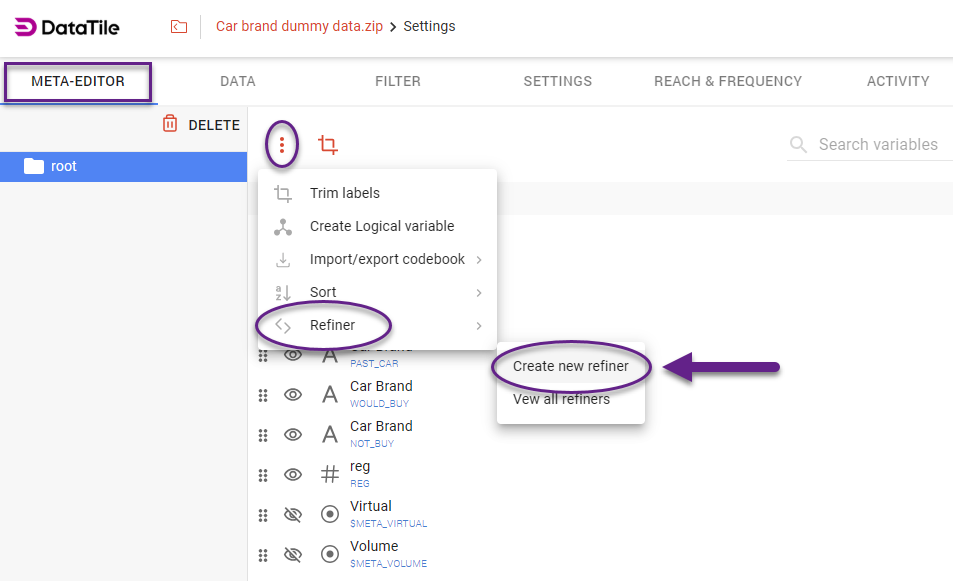
Select variables that should be involved in coding. You may select several variables, including categorical ones, but at least one of them should be a text variable. Drag and drop them into the central area. Once all variables are added, click ‘Proceed’.
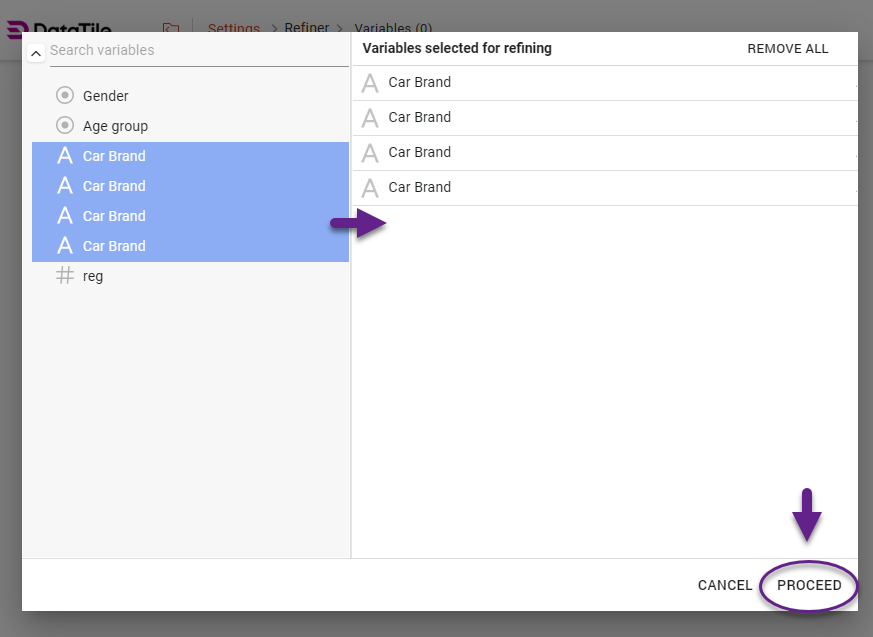
Refiner Interface
When a dictionary is first loaded into the Refiner, it includes all content from the text variables. This is where you begin working with the data if you don’t yet have existing dictionaries or rules.
If you have saved dictionaries and rule sets, you can reuse them for a new database. A saved Refiner functions as a data-processing script: the system first applies dictionaries, then rules.
The core functionality of the Refiner lies in clustering — merging all relevant word or sentence variants into a single category and standardizing their representation. Clustering can be performed manually, using algorithms, or through rule-based automation.
If you upload a categorical variable along with text variables, the categories of that variable will automatically be treated as ready-to-use clusters.
Manual clustering
The main challenge with open-ended responses is that their spelling may be inconsistent, containing typos, abbreviations, or slight variations. In manual coding, you typically rely on a few key letters in a word as the basis for finding all relevant variants.
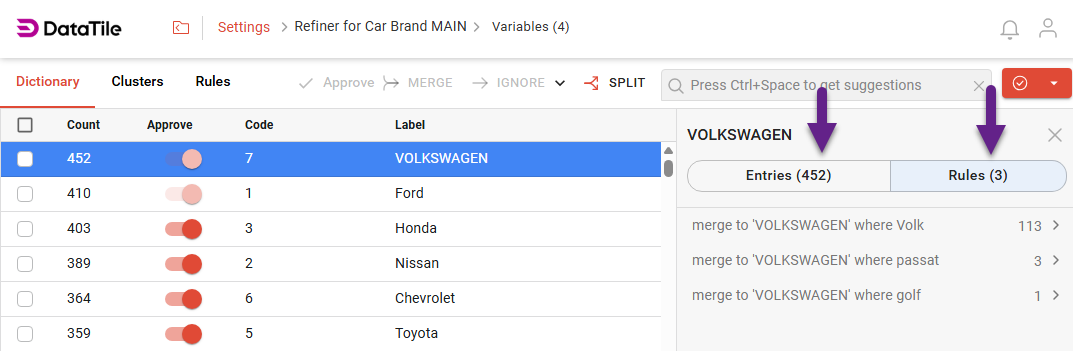
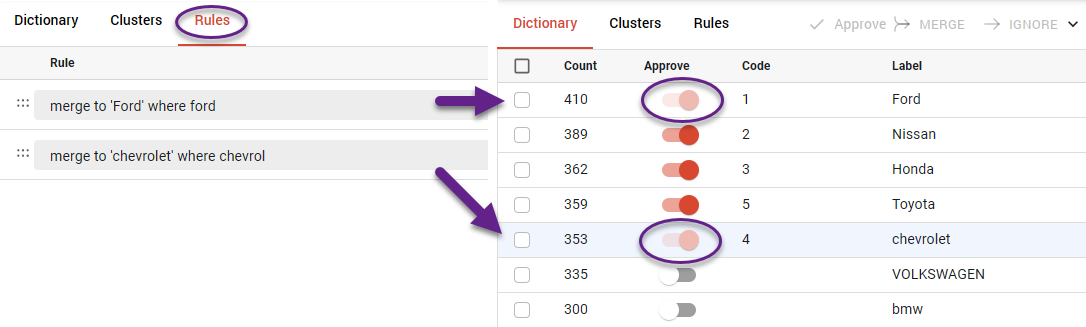
For example, when coding answers to a question about car brands, you may encounter many different spellings, but most of them can likely be found by searching for the substring ‘Volk’.
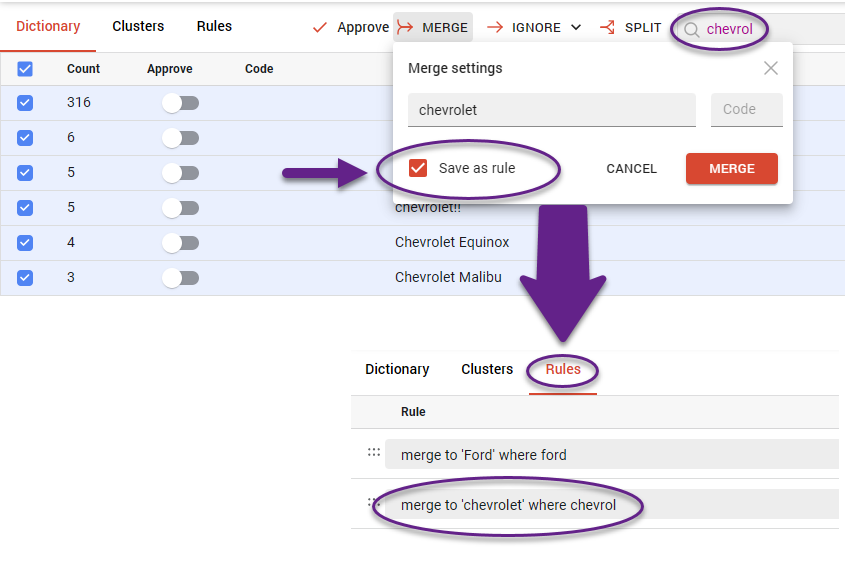
During manual clustering, you enter keywords into the search field to find all relevant matches. After reviewing them, you can select all and merge them into a single cluster.
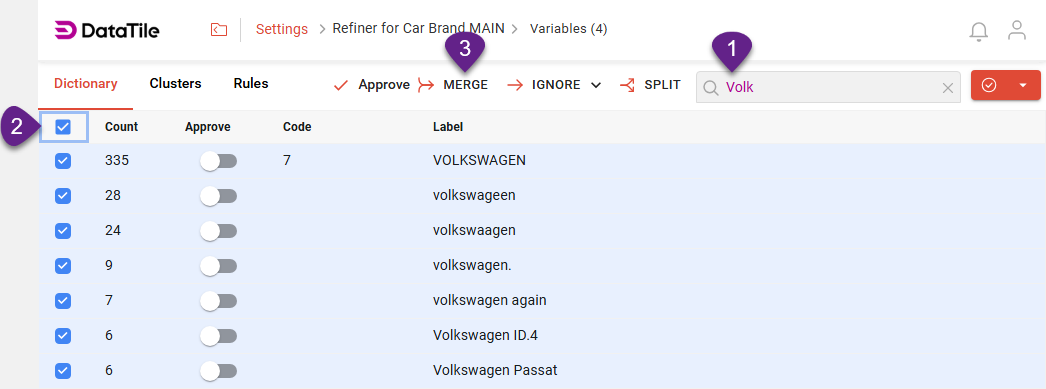
When this is done, your dictionary is automatically updated: all words included in the cluster are saved, and you can view or edit the cluster’s contents at any time.
An approved cluster receives a category code, which can also be edited along with the cluster label.
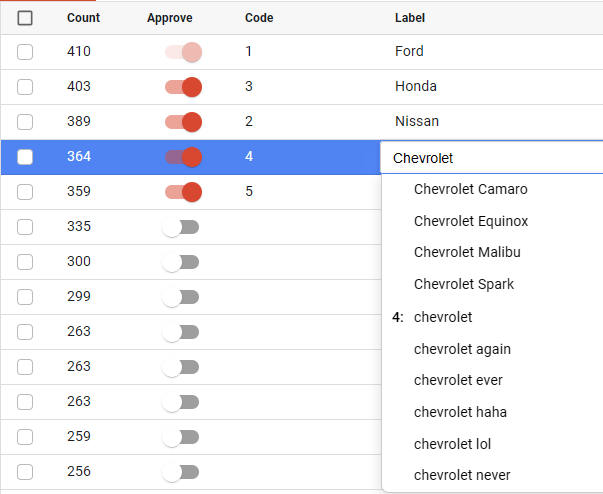
By selecting entries on the Dictionary tab, you can perform several other operations:
-
Approve selected (each entry will be approved separately).
-
The Ignore command marks the selected items as SYSMIS.
-
If a text variable contains multiple responses within a single line, you can split them using the Split command and specifying a delimiter.
The Dictionary tab stores all created clusters, including those generated through algorithms and by applying rules. Additional entries can be freely added to existing clusters as needed.
When a cluster is selected, its content is displayed in the panel on the right. You can review the words included in a cluster under the Entries tab (which represents the dictionary), or the Rules tab (displays the content of each applied rule), and delete them if necessary.
We recommend starting the merging process on the Clusters tab, as clusters are generated automatically and can be merged immediately after review.
Clustering with similarity algorithms
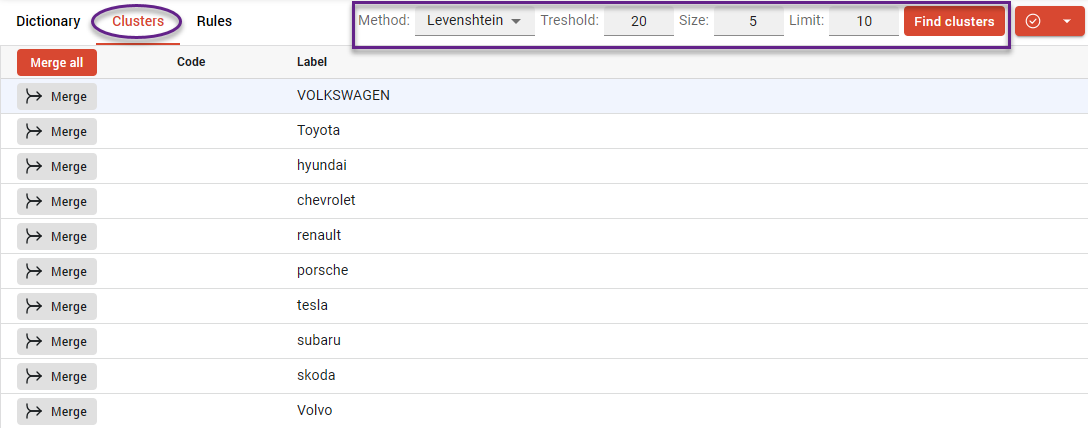
In the Cluster tab, all matching occurrences are gathered and presented as potential clusters based on the selected algorithm. You can also adjust the clustering algorithm and parameters directly from this section.
For automatic cluster generation, you can use any of the following word similarity algorithms:
-
Levenshtein
-
Jaro-Winkler
-
Damerau
-
Cosine
-
Sorensen-Dice
-
The threshold is defined as a distance value, which specifies the maximum allowed difference between words for them to be grouped into the same cluster. In this case, lower values indicate stricter matching, meaning only highly similar words will merge, while higher values allow for greater variation and result in broader clusters.
-
Size (length) defines the minimum word length required for inclusion in a cluster. This parameter helps filter out ‘garbage’ entries such as fragments, short syllables, or incomplete words.
-
The limit defines the maximum number of clusters that can be generated from the dataset. The value can range up to 25, meaning that no more than 25 clusters will be formed at once, even if additional potential groups are detected.
Clusters that have already been approved are hidden from the Clusters tab. This view only displays those that still require processing.
Clustering using rules
You can define rule-based scenarios for automated coding. Rules can be created either during the merging process, as shown in the example below, or manually.
To create a new rule manually, go to the Rules tab and click the ‘Add’ button.
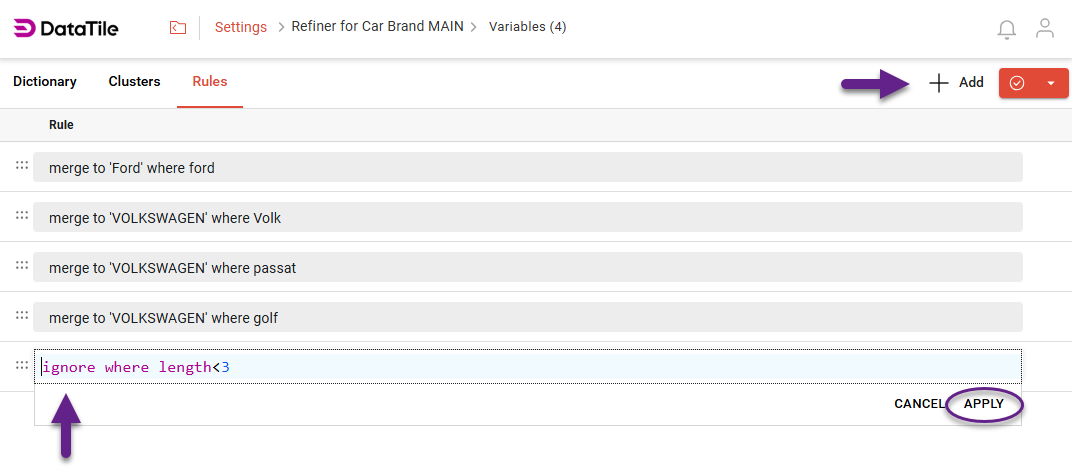
Rules can be individual (applying to a single cluster) or global, affecting the entire dictionary. For example, rule merge to 'Ford' where ford indicates a certain cluster, while ignore where length<3 will be applied globally.
A rule ‘Ignore’ will mark any matching words as SYSMIS.
On the Rules tab, the order of rules in the list is important, as they are applied sequentially from top to bottom. Once a word matches a specific rule, no other rules will be applied to it, even if their conditions are also met. Therefore, it’s recommended to keep only relevant and necessary rules and avoid creating similar or duplicate ones.
When a rule is triggered, it approves the corresponding target cluster, and this action cannot be undone unless the corresponding rule is deleted.
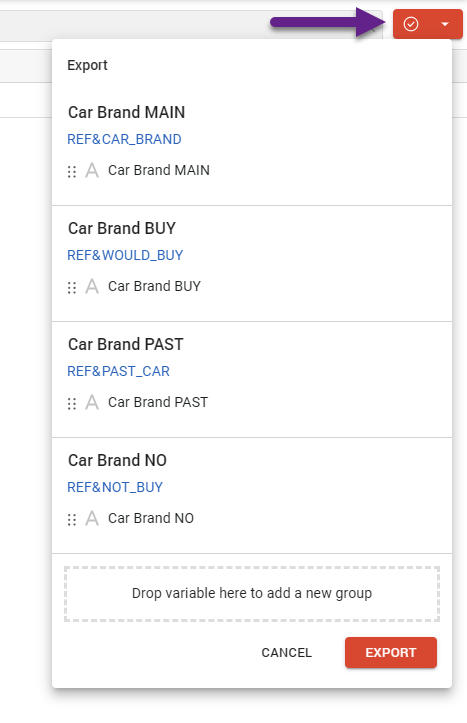
Export
Once all necessary clusters are created and all entries are assigned, you can export the result as a separate variable in the Meta-Editor using an Export button.
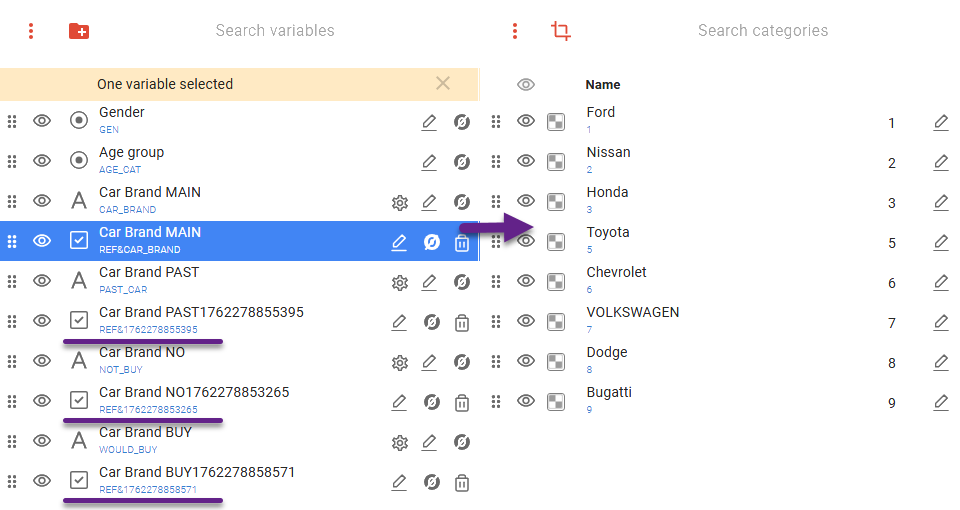
After export, you’ll find these new categorical variables generated from the clusters in the list with the REF prefix in their codes.
You can also define the number of categories to be exported. In the export window, simply group or ungroup the variables as needed (see the illustration below).
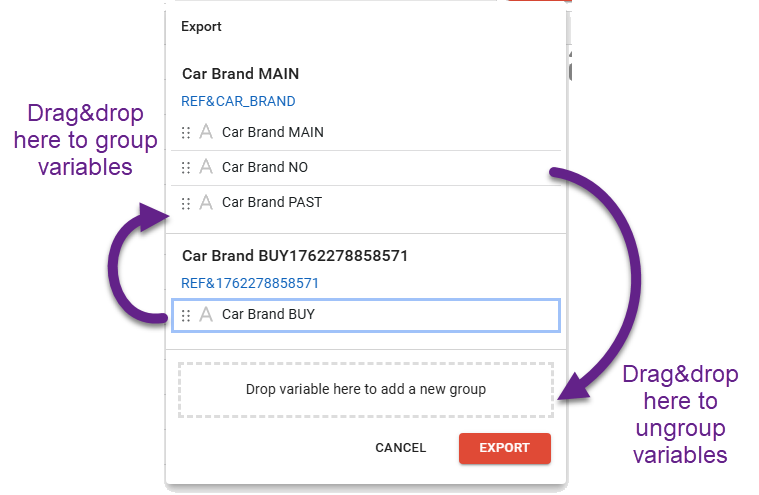
For example, if you initially had four text variables, you can export them as a single combined categorical variable.